



.png)
.webp)
Financial fraud keeps evolving. So do the ways people try to catch it. Card fraud, account takeover, fake claims, loan abuse — the list is long, and it gets messier every year. Fraud detection in data mining is one of the most practical ways to deal with it. It uses pattern discovery, classification, clustering, and anomaly detection to spot suspicious behavior in large datasets before the damage spreads.
Wikipedia describes fraud detection as a knowledge-intensive activity, and that fits. The work is not just about models. It is about data, context, and the weird little signals that show up before a fraud case becomes obvious.
You will also get to know about Nected, a leading provider of data mining and fraud detection solutions.

What Is Fraud Detection in Data Mining?
Fraud detection in data mining is the use of data mining techniques like classification, clustering, and anomaly detection to identify fraudulent transactions or behavior in large datasets. It helps surface patterns that would be hard to catch by hand. That is the short version. The longer one is that it works on messy, shifting data where fraud does not always look like fraud at first glance.
It shows up in banking, insurance, healthcare, e-commerce, and anywhere suspicious activity leaves a trail. The point is not just to catch known fraud. It is to catch the odd stuff before it becomes a bigger problem.
In credit card fraud, for example, the system watches for unusual spending, strange locations, or behavior that does not fit the normal pattern. This part often gets ignored until losses stack up.
How Data Mining Is Used for Fraud Detection
The process usually starts with data collection. Transaction logs, account activity, user behavior, financial records — all of it matters, depending on the fraud type. The more complete the data, the better the chance of finding something useful. But raw data is never ready as-is.
Next comes preprocessing. Missing values, duplicate records, inconsistent formats, and heavy class imbalance need to be handled early. Fraud data is usually skewed hard, so the minority class gets buried fast if you do not clean things properly.
Then comes pattern discovery. Some teams use supervised methods when they have labeled fraud cases. Others use clustering or anomaly detection when labels are thin or unreliable. In real systems, both often show up together.
The last step is alerting and action. Some models flag transactions in real time. Others feed batch review queues. The difference matters. Real-time systems need speed and tight thresholds. Batch review gives analysts more room to dig, which is where things usually break if the workflow is not built well.
Also Read: Risk Management Tools
Key Data Mining Techniques for Fraud Detection
Decision Trees
Decision trees are easy to explain and easy to deploy. That makes them useful when investigators need to know why a transaction was flagged. They work well as a baseline model, especially when the fraud rules are relatively clear.
Neural Networks
Neural networks can pick up non-linear relationships that simpler models miss. They are often used when fraud patterns are messy and spread across many signals. The trade-off is less transparency, which can be a problem in regulated environments.
Clustering
Clustering methods like K-Means and DBSCAN group similar transactions together and help isolate outliers. This is useful when fraud does not follow a known label pattern. It also catches odd behavior that the training set never saw.
Association Rule Mining
Association rules look for combinations of events that tend to occur together. In fraud work, that can mean repeated patterns across accounts, devices, locations, or merchants. It is not always the flashiest method, but it can expose repeated schemes.
Bayesian Classification
Bayesian classifiers estimate the probability that a transaction belongs to the fraud class. They are useful when you want probabilistic outputs instead of hard yes-or-no decisions. That makes threshold tuning easier.
Support Vector Machines (SVM)
SVMs are often used for binary classification tasks where the separation between normal and fraudulent behavior is fairly strong. They can perform well on structured data, though scaling and tuning can get annoying on larger fraud datasets.
Graph Neural Networks (GNNs)
GNNs are useful when fraud is coordinated across accounts, devices, or transactions. They can uncover hidden fraud rings by looking at relationships instead of just rows in a table. This is the part that catches a lot of modern fraud setups.
Fraud Detection Data Science
Fraud detection data science is the full pipeline, not just model training. It starts with feature engineering. Velocity features, ratio features, and behavioral deviation signals are usually more valuable than raw transaction fields. A card being used three times in two minutes says more than a card being used three times, full stop.
Then comes class imbalance. Most fraud datasets are tiny on the fraud side, so standard training can go sideways fast. Techniques like SMOTE and class_weight help, but they are not magic. They just stop the model from ignoring the minority class.
Model selection is the next decision. XGBoost often works well on tabular fraud data. Isolation Forest is useful when labels are weak or unavailable. Picking the model depends on the data shape and the latency you can afford.
Accuracy is usually the wrong metric here. A model can be 99.9% accurate and still be useless if it misses every fraud case. Precision, recall, F1, and ROC-AUC tell a better story. Deployment matters too. Some teams need batch scoring. Others need a real-time API tied to transaction monitoring.
And then there is drift. Fraud patterns change. People adapt. Attackers do too. If the monitoring layer is weak, model performance fades without anyone noticing.
Also Read: Open Source Business Process Management Tools
Top Fraud Detection Datasets
Picking the right fraud detection dataset makes a huge difference. Some are real-world banking datasets. Some are synthetic. Some are good for benchmark comparisons, while others are better for testing scale or relational behavior.
ULB Credit Card Fraud
This is the dataset most people mention first. It has 284,807 European cardholder transactions, with 492 confirmed frauds. The features are PCA-transformed for confidentiality, which makes it useful for benchmarking but not exactly friendly for explanation.
IEEE-CIS / Vesta
This Kaggle competition dataset has 590,540 transactions and a fraud rate of about 3.5%. It is often used for e-commerce fraud work. The tricky part is the size and the amount of missing data, which makes preprocessing do a lot of the heavy lifting.
PaySim Synthetic
PaySim simulates mobile money transactions at scale, with more than 6 million records. It is synthetic, so it is not a perfect proxy for live fraud, but it is helpful for testing pipeline performance and class imbalance handling.
Amazon FDB
Amazon’s fraud benchmark includes multiple datasets across fraud domains like card fraud, bot attacks, and loan risk. It is useful when you want to compare techniques across different problem shapes instead of just one narrow fraud case.
Kaggle Financial Fraud
This dataset contains 594,643 synthetic transactions. People use it for experimentation, especially when they need a sizeable sample without having to deal with private production data.
EDGAR Financial Fraud
EDGAR-based fraud detection focuses on accounting fraud and SEC filings. It is a different kind of problem. The signals live in disclosures, not only in payment behavior.
Challenges in Fraud Detection Data Mining
Severe class imbalance is still the biggest headache. In many datasets, fraud makes up only 0.1% to 5% of the total. That means a model can look good on paper and still miss the cases that matter. Research has shown that SMOTE can improve fraud detection F1-scores a lot, but it depends on the dataset and setup.
Fraud patterns also change over time. Concept drift is real. So are adversarial attacks. A model trained on last quarter’s behavior can get stale fast.
Label scarcity is another issue. A lot of fraud goes unconfirmed, or gets confirmed late. Add feature confidentiality, real-time processing constraints, and explainability requirements, and the whole stack starts to get annoying in a hurry.
Also Read: Operational Risk Management Tools in 2026
Fraud Detection Data Mining Tools & Technologies (2026)
Python is still the default starting point. Scikit-learn covers the basics, XGBoost is strong for tabular data, PyOD helps with anomaly detection, and NetworkX is useful when fraud starts looking like a graph problem.
For scale, Apache Spark shows up a lot. Kafka handles streaming. On the enterprise side, SAS Fraud Management and FICO Falcon are common names. Cloud ML platforms like AWS SageMaker, Azure ML, and Google Vertex AI fit when teams want managed deployment instead of building everything themselves.
Real-World Applications of Data Mining for Fraud Detection by Industry
Banking & Credit Cards
Transaction anomaly detection is the obvious use case here. The IEEE-CIS dataset is a good reference point for this kind of work. Banks use models and rules together because one layer alone usually misses something.
Insurance
Claims fraud is often harder to spot because the data is less structured. Bayesian classifiers and clustering help separate normal claims from suspicious ones. Even a small percentage of false claims can turn into real losses fast.
E-commerce
Account takeover and payment fraud often travel together. Graph analysis is useful when attackers reuse devices, emails, or shipping patterns across accounts. That is where coordinated behavior starts to show.
Healthcare
Billing fraud and abnormal claim patterns are common targets. Clustering can help identify outlier providers or unusual claim bundles. Healthcare data is noisy, and that makes the job harder than people expect.
Telecommunications
Subscription fraud and SIM cloning rely on pattern reuse. Fraud teams use anomaly detection and behavioral scoring to catch churn-like activity that is actually abuse. The losses add up quickly when the issue spreads across many accounts.
Use Cases of Data Mining in Fraud Detection
There are many different businesses where data mining is used to detect fraud. Among the typical use cases are:
1. Fraudulent Transaction Detection: Abnormal or fraudulent activity in transactions, such as those at point of sale (POS) terminals and online purchases, is detected by data mining. Complex algorithms such as decision trees, logistic regression, and neural networks are used to find anomalous patterns in the data, allowing companies to proactively spot and stop fraudulent transactions.
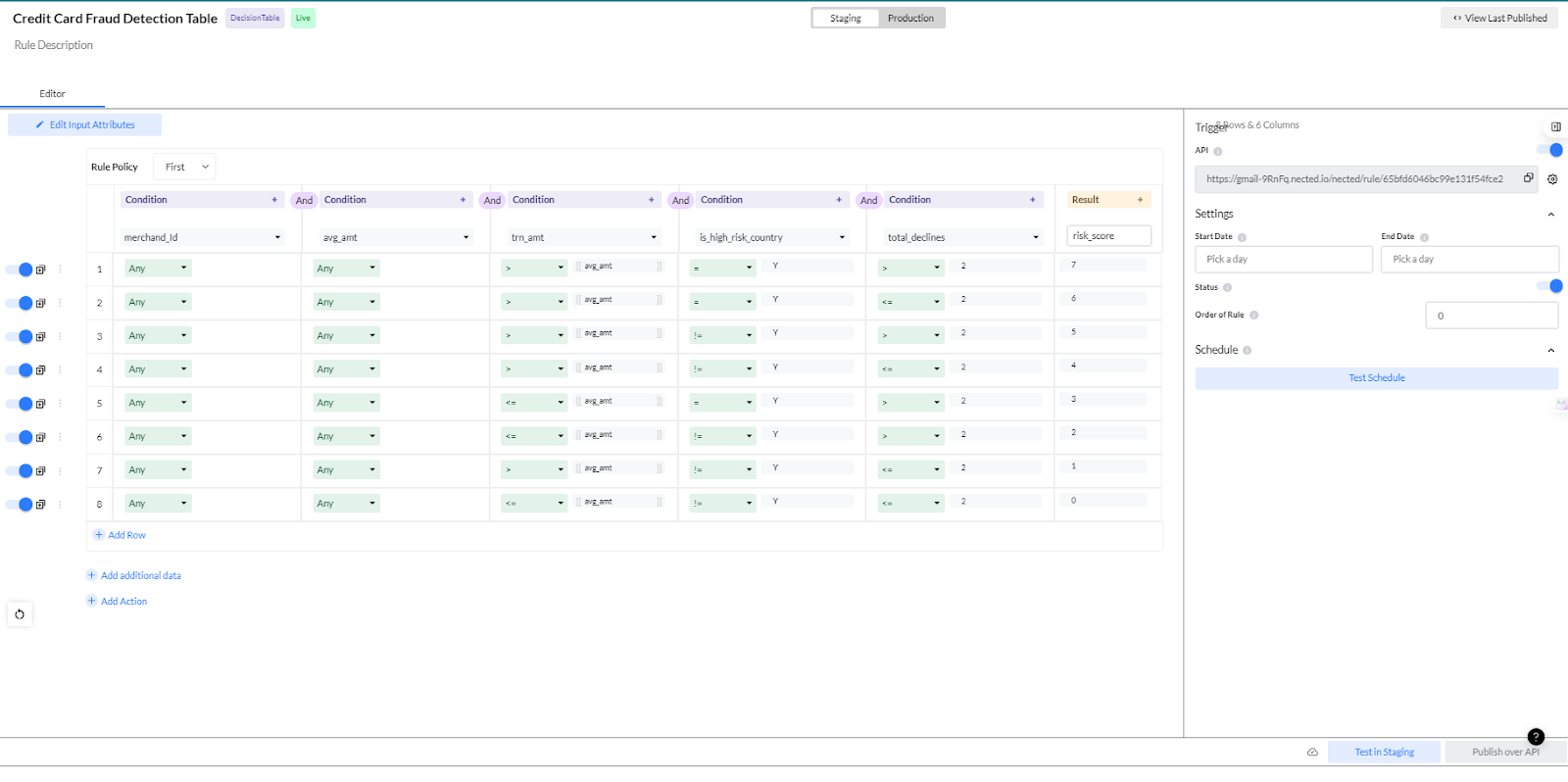
Stop suspicious transactions using Nected! Create basic rules based on quantity, location, device, and time. Nected identifies anything odd for review or immediate blocking. Real-time updates keep you informed, and flexible policies respond to emerging dangers. Nected is more than simply a lead sorting service; it is your financial security ally, simple and effective.
2. Banking and Financial Services: Fraudulent loan applications, odd spending habits, or strange account access are examples of irregular patterns of fraud detection in banking that are found by data mining. Data mining helps mitigate financial losses and maintain the integrity of the financial system by analyzing vast amounts of financial data to identify anomalies across many channels and predict suspicious conduct.
3. Healthcare Fraud Detection: To combat medical claim fraud and abuse, data mining techniques are used to evaluate patient profiles, billing information, and medical claims in order to spot odd patterns or outliers. This use case highlights the value of data mining in reducing fraud risks associated with healthcare and finance.
4. Insurance Fraudlent: Fraud detection using data mining can help in identifying many types of insurance fraud, including upcoding, fake diagnosis, pharmaceutical provider fraud, filing claims for unfulfilled medical services, and fabricating job or eligibility documents in order to receive a reduced premium rate. Data mining helps forecast and detect insurance fraud in real-time by evaluating large volumes of datasets, hence limiting the associated damage.
These use examples highlight the role that data mining plays in detecting and stopping fraudulent actions by illuminating the broad range of applications of data mining in fraud detection across many industries.
How Nected Complements Data Mining for Fraud Detection
Nected is not there to replace fraud models. It sits around them. You can use ML scores as rule inputs, so a transaction gets flagged the moment it crosses a threshold. That is useful when you need action right away instead of waiting for a batch job.
It also helps during retraining. While the model is being updated, rule-based fallbacks keep basic fraud controls in place. This avoids the gap where a model is offline and the business still needs coverage.
And then there is the practical side. Risk and compliance teams can update thresholds without waiting on engineering every time. That part often gets ignored, but it saves a lot of friction when fraud patterns change.
FAQ
What is fraud detection in data mining?
Fraud detection in data mining is the use of data mining algorithms to find suspicious patterns in large datasets. It includes supervised methods like classification, unsupervised methods like clustering and anomaly detection, and hybrid approaches.
What data mining techniques are used for fraud detection?
Common techniques include decision trees, neural networks, clustering, association rule mining, Bayesian classifiers, support vector machines, and graph neural networks. The right one depends on the data and the fraud type.
What are the best fraud detection datasets for machine learning?
ULB Credit Card Fraud, IEEE-CIS / Vesta, PaySim, Amazon FDB, Kaggle Financial Fraud, and EDGAR-based datasets are widely used. ULB is the most cited benchmark, while IEEE-CIS is a strong real-world competition dataset.
How does class imbalance affect fraud detection datasets?
It makes fraud harder to learn because legitimate transactions overwhelm the signal. Accuracy becomes misleading, so teams usually rely on ROC-AUC, F1, precision, and recall. SMOTE and class weighting can help.
What is fraud detection data science?
Fraud detection data science covers the full lifecycle: collecting data, engineering features, training models, evaluating performance, deploying the system, and watching for drift. It is less about a single model and more about the whole pipeline.
What is the ULB credit card fraud detection dataset?
It is a benchmark dataset with 284,807 European cardholder transactions and 492 confirmed frauds. The features are PCA-transformed, so the data protects confidentiality while still allowing model benchmarking.
What tools are used for data mining in fraud detection?
Python, scikit-learn, XGBoost, PyOD, NetworkX, Apache Spark, Apache Kafka, SAS Fraud Management, FICO Falcon, and cloud ML platforms like SageMaker, Azure ML, and Vertex AI are common choices.
How can Nected be used alongside fraud detection data mining models?
Nected can take model scores and turn them into live rules for flagging, review, or escalation. It also gives compliance teams a way to adjust thresholds without waiting on a full redeploy.





.svg.webp)











.webp)




%252520(1).webp)







%20(1).webp)
