



.png)
.webp)
Its very normal for a business that its business rules can constantly be modified. Pricing logic, eligibility criteria, approval thresholds — the rules that govern application behavior tend to shift faster than development cycles allow. Hardcoding this logic into application code works until it doesn't, and then you're stuck pushing deployments every time a business stakeholder wants to tweak a condition.
JSON rule engines address this by separating decision logic from application code. Rules live in JSON structures, get evaluated at runtime, and can be updated without touching the core codebase. The json engine pattern shows up across teams building anything from fraud detection to content personalization to workflow automation.
This is a practical look at how JSON rule engines work, how to build them, where they break down, and what a json decision model actually looks like in practice.
What Is a JSON Decision Model
A JSON decision model is a structured representation of decision logic in JSON format. Instead of writing if/else chains in your application code, you express conditions, operators, and outcomes as data. The engine reads that data at runtime and evaluates it against current facts.
A simple example. You have a rule: if a user's account age is greater than 30 days AND their purchase count is greater than 3, flag them as a trusted customer. In a json decision model, that looks something like this:
{
"conditions": {
"all": [
{
"fact": "accountAgeDays",
"operator": "greaterThan",
"value": 30
},
{
"fact": "purchaseCount",
"operator": "greaterThan",
"value": 3
}
]
},
"event": {
"type": "trustedCustomer"
}
}
The model is readable. Non-engineers can look at it and understand what it's doing. That's the point. Decision models that live in code are invisible to the people who own the business logic — they have to ask a developer every time they want to see or change a rule.
JSON decision models solve a communication problem as much as a technical one.
Also Read: Top 10 Open Source Rule Engine
What Is a JSON Rules Engine
At its core, a JSON rules engine is a runtime evaluator for JSON decision models. You give it a set of rules and a set of facts. It evaluates each rule against the facts and fires events when conditions are met.
The rules themselves are defined using JSON. Conditions can be nested — all for AND logic, any for OR logic. Facts are the runtime data: user attributes, transaction values, system state, whatever the rules need to evaluate against.
Rules stay separate from application code. That separation is the whole value proposition. Teams can change, add, or remove rules without a deployment. The engine handles evaluation; the application handles what happens when an event fires.
A few things worth knowing upfront. JSON rule engines are not databases. They don't store state between evaluations. Each call is stateless — you pass in facts, you get events back. Anything stateful (tracking how many times a rule has fired, historical data) lives outside the engine.
Also, rule priority matters more than it looks at first. Most engines evaluate rules in definition order, but when rules start overlapping or conflicting, execution order becomes critical. Teams underestimate this until they hit a production bug caused by two rules firing on the same conditions in the wrong sequence.
JSON Rule Engine Architecture
The architecture isn't complicated, but getting it right takes thought. Here's how most of the production implementations are structured.
Rule Storage: Rules live somewhere external to the application — a database, a configuration file, an admin interface. The engine loads them at startup or fetches them on demand. Storing rules in code defeats the purpose.
Fact Providers: Facts are the runtime inputs the engine evaluates against. In simple implementations, facts are passed in as a plain object. In more complex systems, facts are computed lazily — the engine only fetches a fact when a rule actually needs it. This matters for performance when you have expensive data lookups.
Rule Evaluator: The evaluation engine itself. It takes the rule set and fact set, traverses the conditional tree, and then determines which rules evaluate to true. The proces is usually recursive and nested any/all conditions get evaluated depth-first.
Event Dispatcher: When a rule's conditions evaluate to true, it fires an event. The application listens for events and decides what to do — trigger a workflow, update a record, send a notification, block a request. The engine fires; the application acts.
Rule Management Layer: Optional but important in practice. A UI or API for creating, editing, and versioning rules without touching code. Without this, the "rules separate from code" promise breaks down, someone still has to edit JSON files manually and redeploy.
A rough architecture:
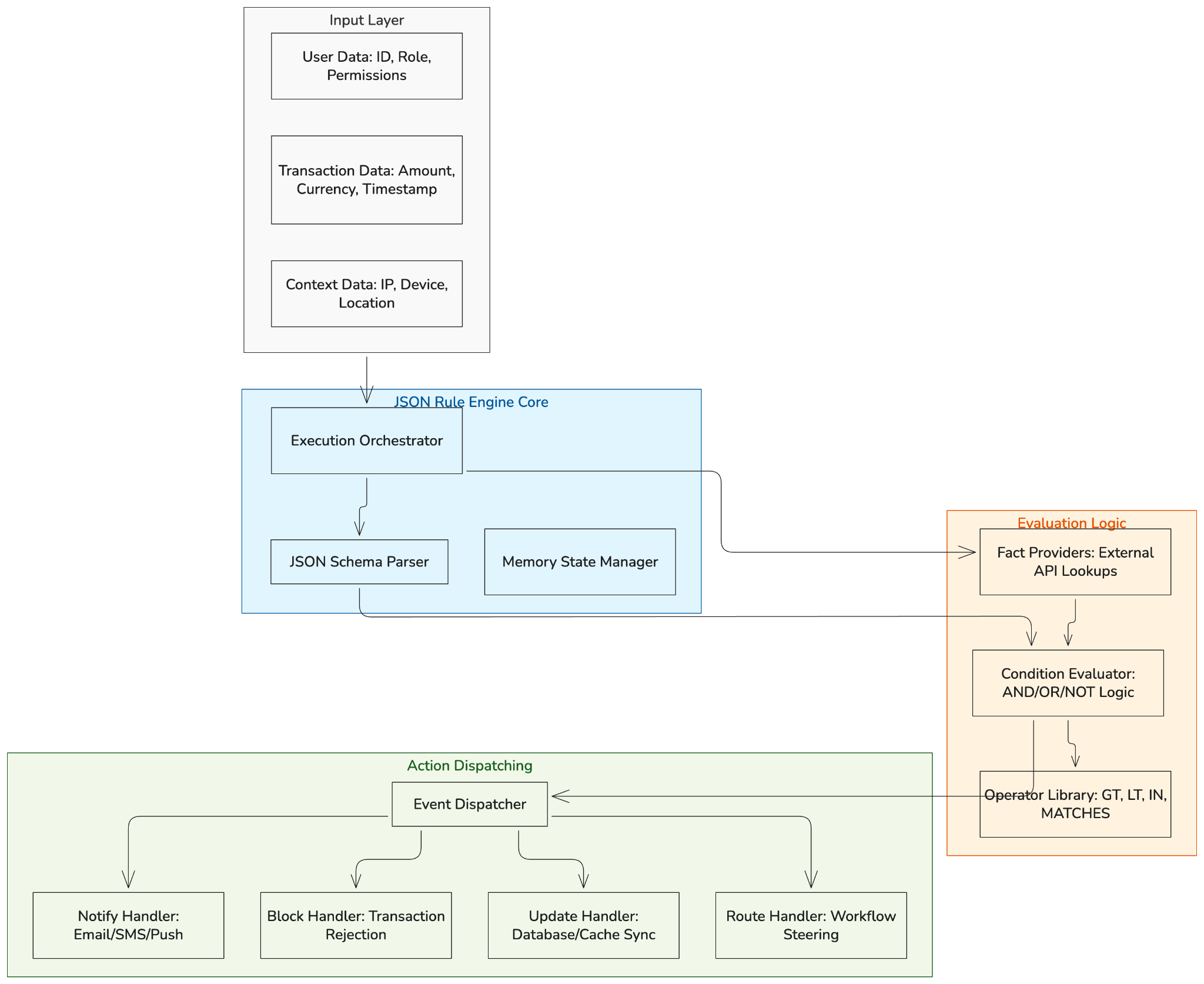
The pieces are simple. Integration is where most of the work actually happens.
Also Read: Rule Engine Design Pattern
Implementing json-rules-engine in Node.js
If you are tired of writing nested if/else statements in your route handlers, json-rules-engine is the standard lightweight escape hatch for Node.js. It doesn't require standing up a massive enterprise Java server. It just evaluates a JSON payload against a set of JSON rules.
Here is how you actually implement it to rip hardcoded business logic out of your core application.
Step 1: Install the Package
It is a lightweight dependency. Drop it into your backend project.
npm install json-rules-engine
Step 2: Initialize and Define a Rule
Instead of writing executable code, you define your logic as a JSON schema. This schema explicitly maps out the conditions and the resulting event.
Here is a practical example. We want to trigger a "Free Shipping" event, but only if the user is a VIP and their cart total is strictly greater than $100.
const { Engine } = require('json-rules-engine');
// 1. Initialize the engine
const engine = new Engine();
// 2. Define the rule as a JSON object
const freeShippingRule = {
conditions: {
all: [
{
fact: 'userType',
operator: 'equal',
value: 'VIP'
},
{
fact: 'cartTotal',
operator: 'greaterThan',
value: 100
}
]
},
event: {
type: 'free-shipping',
params: {
message: 'User qualifies for free VIP shipping!'
}
}
};
// 3. Load the rule into the engine
engine.addRule(freeShippingRule);
Step 3: Feed the Facts and Execute
The engine needs data—called "facts"—to evaluate against the rule. In a real-world scenario, this is just the req.body from your API or a payload pulled from your database.
You pass the facts into the run() method. The engine evaluates the graph and returns any events that successfully triggered.
// 4. Define the runtime data (Facts)
const facts = {
userType: 'VIP',
cartTotal: 150
};
// 5. Run the engine
engine
.run(facts)
.then(({ events }) => {
events.map(event => {
console.log(`Success! Event triggered: ${event.type}`);
console.log(`Message: ${event.params.message}`);
// Output: Success! Event triggered: free-shipping
});
})
.catch(err => {
console.error('Engine crashed during evaluation:', err);
});
Why Do It This Way?
If you look at the freeShippingRule object above, you'll notice it's just pure data. It isn't executable JavaScript.
This means you don't have to keep the JSON object in your codebase, rather you can simply store it in a Postgres database or an S3 bucket. When the marketing team decides to raise the free shipping threshold to $150, you can just update the JSON in the database.
The rule engine pulls the new JSON, evaluates the next incoming payload, and adjusts the business logic accordingly and instantly. You don't have to touch a single line of code, or open a pull request, or wait for a CI/CD pipeline to deploy.
JSON Rule Engine in Java
Java doesn't have a widely dominant json rules engine library the way Node.js does with json-rules-engine. Most Java teams either implement a lightweight engine themselves or use a broader rule engine like Drools with JSON-based rule definitions layered on top.
A minimal Java implementation follows the same structural pattern. You define nodes for conditions, an evaluation context that holds facts, and a recursive evaluator that walks the condition tree.
interface Condition {
boolean evaluate(Map<String, Object> facts);
}
class ComparisonCondition implements Condition {
private final String fact;
private final String operator;
private final Object value;
public ComparisonCondition(String fact, String operator, Object value) {
this.fact = fact;
this.operator = operator;
this.value = value;
}
@Override
public boolean evaluate(Map<String, Object> facts) {
Object factValue = facts.get(fact);
if (factValue == null) return false;
switch (operator) {
case "greaterThan":
return ((Number) factValue).doubleValue() > ((Number) value).doubleValue();
case "equal":
return factValue.equals(value);
case "lessThan":
return ((Number) factValue).doubleValue() < ((Number) value).doubleValue();
default:
throw new IllegalArgumentException("Unknown operator: " + operator);
}
}
}
class AllCondition implements Condition {
private final List<Condition> conditions;
public AllCondition(List<Condition> conditions) {
this.conditions = conditions;
}
@Override
public boolean evaluate(Map<String, Object> facts) {
return conditions.stream().allMatch(c -> c.evaluate(facts));
}
}
class AnyCondition implements Condition {
private final List<Condition> conditions;
public AnyCondition(List<Condition> conditions) {
this.conditions = conditions;
}
@Override
public boolean evaluate(Map<String, Object> facts) {
return conditions.stream().anyMatch(c -> c.evaluate(facts));
}
}
You'd add a rule class that wraps a condition with an event definition, a parser that converts JSON into condition trees, and an engine class that runs rules against a fact map and collects fired events.
The JSON parsing step is usually handled with Jackson or Gson. The structural challenge is building a parser that handles arbitrary nesting — conditions within conditions within conditions. Recursive descent works, but it needs to handle malformed input gracefully. This is where things usually break in early implementations.
Also Read: Top 7 Java Rule engine
JSON Rule Engine Example
Here's a complete example using the Node.js json-rules-engine library. The scenario: detecting when a basketball player has fouled out based on game duration and personal foul count.
const { Engine } = require('json-rules-engine')
let engine = new Engine()
// Foul out if: (5 fouls AND 40min game) OR (6 fouls AND 48min game)
engine.addRule({
conditions: {
any: [{
all: [{
fact: 'gameDuration',
operator: 'equal',
value: 40
}, {
fact: 'personalFoulCount',
operator: 'greaterThanInclusive',
value: 5
}]
}, {
all: [{
fact: 'gameDuration',
operator: 'equal',
value: 48
}, {
fact: 'personalFoulCount',
operator: 'greaterThanInclusive',
value: 6
}]
}]
},
event: {
type: 'fouledOut',
params: {
message: 'Player has fouled out!'
}
}
})
let facts = {
personalFoulCount: 6,
gameDuration: 40
}
engine
.run(facts)
.then(({ events }) => {
events.map(event => console.log(event.params.message))
})
// Output: Player has fouled out!
The any/all nesting handles the OR/AND logic. The engine evaluates both branches. The first branch: gameDuration === 40 is true, personalFoulCount >= 5 is true — that branch fires. The event gets dispatched.
Notice that the facts object is flat. The engine handles the complex condition tree; facts stay simple. This is a deliberate design choice in most json rule engines — keep fact resolution simple, put complexity in the rule definitions.
One thing this example glosses over: what happens when facts need to be fetched asynchronously? Most production systems don't have all facts available upfront. The json-rules-engine library supports async fact providers — functions that return promises. That changes the integration pattern significantly and adds complexity to error handling.
The Challenges With JSON Rules Engines
This section is worth being direct about. JSON rule engines solve real problems, but they introduce new ones.
- Debugging is harder than expected. When a rule fires unexpectedly (or doesn't fire when it should), tracing through nested condition trees without tooling is painful. You need logging at the condition evaluation level, not just at the event level.
- Rule conflicts are invisible until production. Two rules that overlap — both evaluating the same fact combinations — can fire in unexpected orders. Most engines don't detect conflicts automatically. This is where things usually go wrong in complex rule sets.
- Complexity creeps in. Rules start simple. Over time, teams add exceptions, edge cases, and nested conditions. The JSON becomes hard to read and harder to maintain. Without a rule management UI, you end up with sprawling JSON files that nobody wants to touch.
- Testing is non-trivial. Testing individual rules in isolation is fine. Testing interactions between 50 rules with overlapping conditions is genuinely hard. Teams underestimate this part.
- Version control for rules. If rules live in a database, standard git-based version control doesn't apply. You need your own versioning and rollback mechanism. If rules live in files, deployment is back in the picture.
None of these are dealbreakers. They're just real costs that don't show up in the getting-started docs.
Also Read: Building a Workflow Engine with PHP
Where Nected Fits?
Nected takes a different path. Instead of manually wrestling with JSON rule definitions—which always leads to versioning nightmares and deployment friction—you build rules through visual interfaces. Decision tables, workflows, condition builders. The platform handles the underlying evaluation.
If you want the benefits of separating rules from your core code but don't want to build your own deployment pipelines, versioning systems, and conflict resolution logic (teams always underestimate the effort here), it's a solid choice. You let non-tech people handle the logic. Developers don't have to be in the loop for every single tweak or minor condition update.
There is a tradeoff on control, obviously. A hand-built engine is fully customizable. You own everything—the evaluation logic, the fact providers, the event handling. Nected is a managed environment. It fits 90% of use cases, but maybe not some hyper-specialized requirement where you need to hook into the engine's internals. For most, especially where business rules change faster than dev sprints, it just makes operational sense.
The specific shift here:
- Low-Code, No-Code approach. This is about getting the rules out of the codebase. It empowers people outside the engineering bubble to set up and change rules without a PR. It cuts the dependency on developers, which is where most projects stall anyway.
- Accessibility for non-tech users. PMs or growth teams can actually jump in and modify things. It changes the dynamic from "file a ticket and wait" to actual collaboration. This usually fixes the communication gap that kills production logic.
- Workflow automation is baked in. It’s more than just a simple rule engine. You can launch dynamic workflows fast, which is great for experimentation. This is where things usually go wrong in manual setups—trying to string together rules into a coherent flow.
- Faster time to market. Shorter cycles mean you actually respond to what’s happening. When development cycles are too slow for the pace of business changes, the system becomes a bottleneck. This moves the path from ideation to execution much faster.
To see how the implementation actually looks in practice, check the Nected docs.
FAQs
What is a JSON rule engine?
A JSON rule engine is a runtime system that evaluates business rules defined in JSON format against a set of facts and fires events when conditions are met. Rules stay separate from application code, which means they can be updated without code changes or deployments.
How do JSON decision models work?
A JSON decision model represents decision logic as structured data — conditions, operators, and outcome events — rather than as code. The rule engine reads the model, evaluates each condition against runtime facts, and dispatches events for rules that evaluate to true.
Can JSON rule engines be used in Java?
Yes. Java doesn't have a single dominant library for this, but the pattern is straightforward to implement. You define condition types as classes, build a JSON parser that converts rule definitions into condition trees, and write a recursive evaluator. Libraries like Jackson handle the JSON parsing; the evaluation logic is custom.
What are the benefits of JSON-based rule engines?
The main benefits are separation of concerns (rules don't live in application code), readability (JSON conditions are understandable without deep technical knowledge), and runtime flexibility (rules can change without deployment). For teams that change business logic frequently, these benefits are significant.
What's the difference between a JSON rule engine and a workflow engine?
A rule engine evaluates conditions and fires events — it answers "does this situation match these criteria?" A workflow engine manages process execution over time — it answers "what happens next in this sequence?" They're often used together: a rule engine decides what path to take; a workflow engine executes the steps along that path.
How do you handle rule conflicts in a JSON rule engine?
Most engines evaluate rules in order and don't automatically detect conflicts. The practical approaches are: defining explicit rule priorities, using rule grouping so conflicting rules don't run together, and adding logging at the condition evaluation level so unexpected firing patterns are visible. There's no built-in solution — it requires discipline in how rules are designed and tested.





.svg.webp)





.webp)



.webp)


.webp)

.jpg)

.jpg)

.jpg)





%20(1).webp)
