
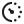



.png)

Credit scoring is a core part of lending. Banks, NBFCs, and other lenders use it to judge how risky an applicant looks before approving a loan or credit card. That usually comes down to past repayment behavior, income, debt, and a few other signals. If you are working with credit scoring in Python, especially on large datasets, this guide should help.
Python comes in handy here because it can handle data prep, modeling, and evaluation without too much friction. It is a practical choice for credit scoring machine learning python workflows, and it works well when you need to test a scoring model python setup across messy, real-world records. This is where things usually break anyway.
We will look at credit risk modelling in python, the models people actually use, and the parts that tend to get ignored until late in the project. There is also a look at a low-code no-code tool Nected, since not every team wants to build everything from scratch.
What Is Credit Scoring in Python
Credit scoring in Python is just the process of building a system that estimates creditworthiness using Python tools and libraries. The score itself can be simple or fairly involved, depending on how much data you have and how strict the lending rules are.
At the basic level, you can write a function that scores an applicant using inputs like age, income, debt, and employment status. That is enough for a toy example. Real systems need more care, more data, and better checks.
Credit Scoring Using Machine Learning in Python
Once the dataset grows, rule-based scoring starts to fall short. Machine learning models can pick up patterns that are hard to capture with a few hand-written rules. In Python, that usually means Pandas for prep and Scikit-Learn for training.
The usual flow is pretty familiar: clean the data, split it, train a model, test it, then look at the results. Random Forest is a common option because it handles mixed signals pretty well. Logistic regression still gets used a lot too, mostly because it is easy to explain. That part often gets ignored, but explainability matters a lot in lending.
Also Read: Open Source Credit Scoring Software
Credit Risk Modeling in Python
Credit risk modeling in Python is broader than just assigning a score. It is about estimating the chance of default, late payment, or some other bad outcome. That can feed into underwriting, pricing, limits, or collections.
In practice, this often means using historical lending data to train a model that predicts whether an applicant is likely to repay. The output may be a probability, a risk band, or a final decision score. The exact shape depends on the lender.
Credit Scoring Models in Python
There are a few common models used in Python-based credit scoring. Logistic regression is still the standard starting point. Random Forest, XGBoost, and other tree-based models are also used when teams want stronger predictive power. Sometimes gradient boosting wins. Sometimes it becomes harder to explain than anyone wanted.
The right model depends on the trade-off between accuracy and interpretability. A lender may prefer a slightly weaker model if it is easier to audit and defend. That is usually the real decision, even if nobody says it that bluntly.
Use Cases of Credit Scoring in Python
Python shows up in a lot of credit workflows. Loan approval is the obvious one, but there is more to it than that.
It can be used for customer risk segmentation, credit limit assignment, pre-qualification checks, and fraud-aware screening. Smaller lenders also use it for internal policy testing before rolling out new scoring logic. If the data is there, Python can usually be pushed into the workflow somewhere.
Evaluating Credit Risk Models in Python
Model evaluation is where people either gain confidence or realize the model is not ready. Accuracy alone is not enough. In credit risk, you usually look at precision, recall, ROC-AUC, confusion matrix results, and sometimes calibration if the probabilities matter.
For lending teams, the bad cases matter more than the average case. Missing risky borrowers can cost real money. So the evaluation needs to reflect that, not just produce a nice-looking number.
Also Read: Credit Scoring Platforms 2026
Building a Credit Scoring Model with Python
Let's build a simple scoring model in Python. This example uses a few basic inputs like age, income, debt, credit history, and employment status. It is not a production model, just a simple starting point.
def calculate_credit_score(age, income, debt, credit_history, employment_status):
# This function takes various parameters as inputs and calculates a credit score.
# Define weights for each parameter
age_weight = 0.2
income_weight = 0.3
debt_weight = 0.2
credit_history_weight = 0.2
employment_status_weight = 0.1
# Calculate the weighted sum
weighted_sum = (age * age_weight) + (income * income_weight) - (debt * debt_weight) + (credit_history * credit_history_weight) + (employment_status * employment_status_weight)
# Map the weighted sum to a credit score scale (e.g., 350 to 800)
min_score = 350
max_score = 800
# Ensure the calculated score is within the defined range
credit_score = max(min_score, min(max_score, weighted_sum))
return credit_score
# Sample usage
applicant_age = 30
applicant_income = 60000
applicant_debt = 10000
applicant_credit_history = 3 # Years of credit history
applicant_employment_status = 1 # Employed (1) or unemployed (0)
# Get credit score
result = calculate_credit_score(applicant_age, applicant_income, applicant_debt, applicant_credit_history, applicant_employment_status)
# Print the result
print("Credit Score: {result}")
In this basic example, we've considered additional parameters like credit history and employment status, each with its own weight. The function returns a credit score within the range of 350 to 800.
Now, when you move into larger datasets, the process gets more involved. You need data prep, model selection, and some kind of predictive layer if you want the score to be useful in a real lending flow.
Data Preparation
The foundation of any credit scoring model is the data. Python, with Pandas, is usually where people start. The code below shows a typical cleaning and preprocessing routine.
import pandas as pd
from sklearn.model_selection import train_test_split
# Load the dataset
credit_data = pd.read_csv('credit_data.csv')
# Handle missing values
credit_data = credit_data.dropna()
# Encode categorical variables
credit_data = pd.get_dummies(credit_data, columns=['education', 'employment_status'])
# Normalize numerical features
credit_data['income'] = (credit_data['income'] - credit_data['income'].mean()) / credit_data['income'].std()
# Split the data into features and target variable
X = credit_data.drop('target_variable', axis=1)
y = credit_data['target_variable']
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
This covers the usual steps: loading the data, dealing with missing values, encoding categories, and normalizing numeric features. Nothing fancy. But without this part, the model quality drops fast.
Model Selection and Training
Python makes model selection manageable because the ecosystem is broad. For credit scoring, Random Forest is a common choice. It usually gives decent results without too much setup.
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
# Create a Random Forest Classifier
model = RandomForestClassifier()
# Train the model
model.fit(X_train, y_train)
# Make predictions
y_pred = model.predict(X_test)
# Assess accuracy
accuracy = accuracy_score(y_test, y_pred)
print(f'Model Accuracy: {accuracy}')
Here, the model is trained, predictions are made, and accuracy is checked. Scikit-Learn keeps the workflow simple enough that teams can move quickly without reinventing the basics.
Predictive Analytics Integration
Python also fits well when you want to layer in interpretability. Statsmodels is often used for that. Logistic regression is a common fit because it gives clearer coefficient-level output.
import statsmodels.api as sm
# Add a constant term to the features
X_train = sm.add_constant(X_train)
# Fit the logistic regression model
logit_model = sm.Logit(y_train, X_train)
result = logit_model.fit()
# Print model summary
print(result.summary())
This gives you coefficients, p-values, and a better sense of what the model is actually doing. That helps when the score has to survive internal review or compliance checks.
Challenges of Building Complex Credit Scoring Models using Python
Python is flexible, but building a serious credit scoring system still comes with problems.
1. Large Database Issues: credit projects often involve large datasets with a lot of customer records. That can slow things down and push memory usage up.
2. Normalization Challenges: data often comes in different scales, and getting it into a usable form takes more work than it first looks. This part often gets ignored until the model starts behaving strangely.
3. Model Interpretability: many machine learning models are hard to explain. That becomes a real issue when the model is tied to lending decisions.
4. High Learning Curve: not every team has people who are comfortable with Python, statistics, and model tuning at the same time.
5. Computation Time Issues: larger models and bigger datasets can slow everything down, especially if decisions need to be made quickly.
6. Data Security Concerns: financial data is sensitive, so security and access control matter a lot.
7. Scalability Challenges: what works in a prototype often starts to strain once real volume shows up.
8. Regulatory Compliance: credit decisions need to be explainable and defensible, which adds another layer of pressure.
These issues are why a lot of teams look for something less fragile than a fully custom build.
Also Read: Top Techniques for Credit Assessment
How does Nected create the same complex credit scoring Model easily?
Implementing complex credit scoring models is easier with Nected because a lot of the setup is already handled through a simpler interface.
Here is a step by step implementation with Nected:
Step 1: Logging In

Begin by logging into the Nected platform with your credentials. Access the user-friendly interface designed for intuitive navigation.
Step 2: Versatile Data Integration
Nected's data integration capabilities let you connect to sources like Amazon Redshift and pull in a mix of financial and operational data. That can include credit history, income, and other signals the business already tracks.
Step 3: Rule Creation
Create a custom rule inside Nected to shape the credit scoring logic around your own business criteria. The low-code and no-code setup helps teams move faster without spending time on a full custom build.
Step 4: Testing and Validation
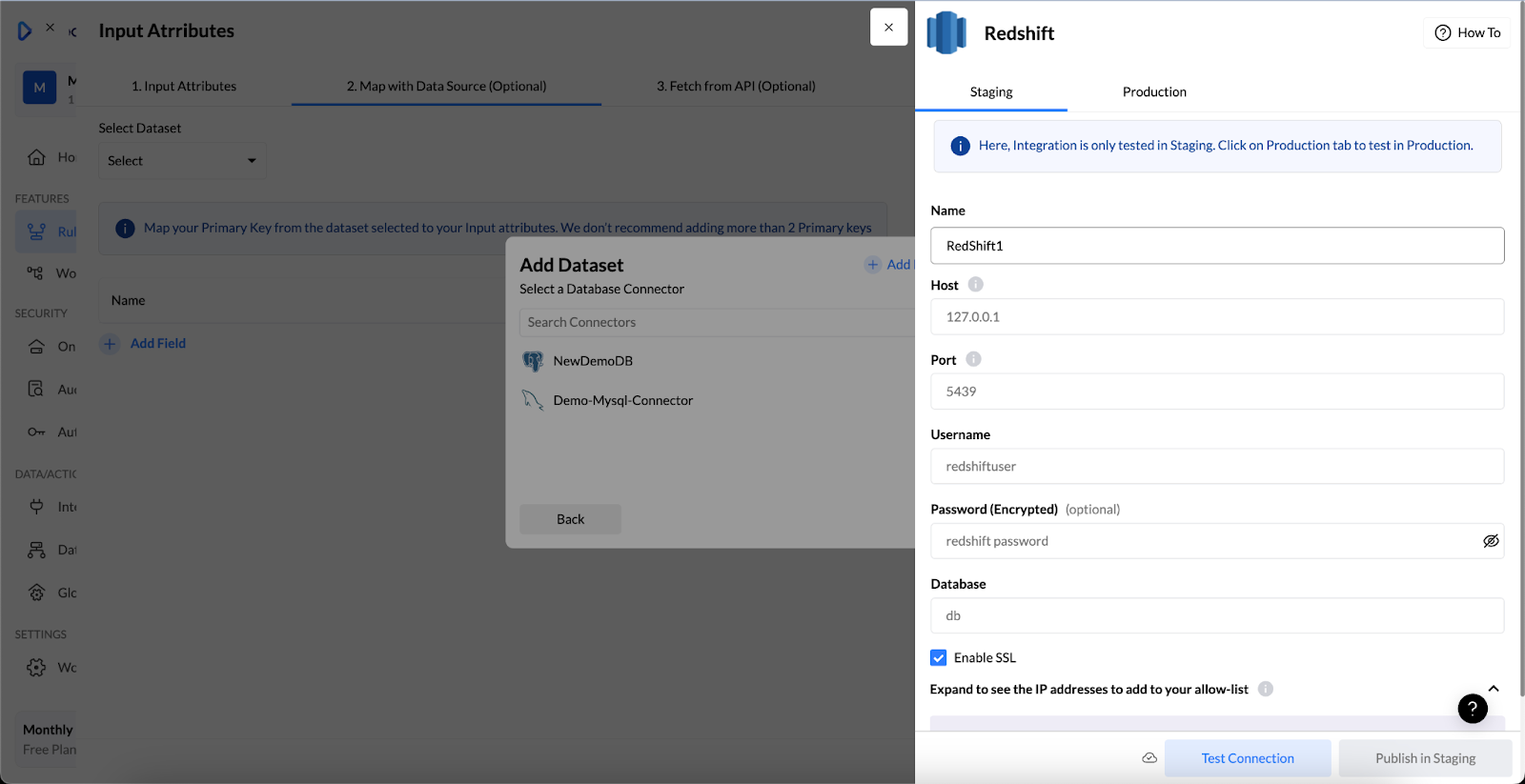
Test the model in Nected before putting it into production. Historical cases are useful here, especially when you want to check whether the rules behave the way you expected.
Step 5: Deployment
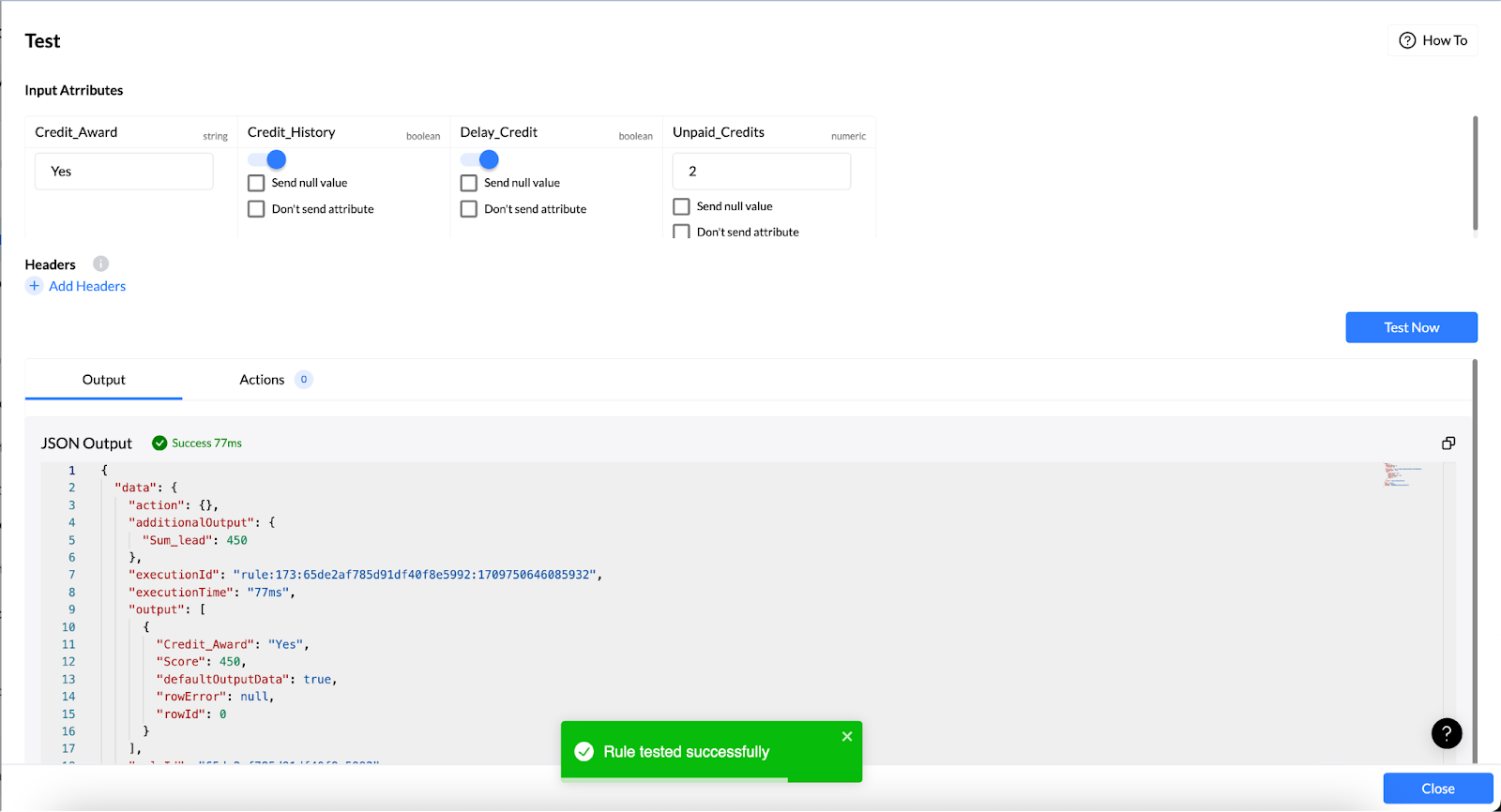
Once the checks look good, deploy the model in Nected and connect it to the lending workflow. That keeps the process moving without a lot of extra glue code.

Nected's user-friendly interface makes this much easier than stitching everything together by hand.
Why use Nected for Creating Credit Scoring Model?
Here is a quick look at why teams choose Nected for credit scoring.
1. Scalability Considerations: as your business grows, Nected can handle more credit applications without forcing a rebuild every time the volume changes.
2. Real-time Rule Execution: decisions can be made with current data, which matters when lending teams need quick responses.
3. User-Friendly Interface: the interface is simple enough for mixed technical teams, and that helps when the work moves between business and engineering.
4. Integration with External Tools: Nected can connect with tools like Gsheet and Slack, so the scoring flow does not have to sit in isolation.
FAQs
What is credit scoring in Python?
It is the process of building a scoring system in Python that estimates how likely someone is to repay credit. The score can come from rules, machine learning, or a mix of both.
How is machine learning used in credit scoring?
Machine learning helps find patterns in historical lending data. Those patterns are then used to predict default risk or repayment behavior for new applicants.
What models are used in credit risk modeling?
Logistic regression is common. Random Forest, gradient boosting, and similar tree-based models are also used when teams want stronger prediction performance.
Which Python libraries are used for credit scoring?
Pandas, NumPy, Scikit-Learn, and Statsmodels are the usual starting point. Some teams also use TensorFlow or PyTorch when the problem gets more complex.
How can I get started with credit scoring using Python if I'm new to programming?
If you're new to programming, start by learning the basics of the Python programming language through online tutorials, courses, or books. Once you're comfortable with Python syntax and concepts, you can dive into specific libraries and tools for data analysis and machine learning, such as Pandas, NumPy, scikit-learn, and TensorFlow.
What are some key libraries and tools in Python that are commonly used for credit scoring?
Commonly used libraries and tools for credit scoring in Python include Pandas for data manipulation, NumPy for numerical computing, scikit-learn for machine learning algorithms, TensorFlow or PyTorch for deep learning, and Matplotlib or Seaborn for data visualization.
How do I preprocess and clean data for credit scoring projects using Python?
Data preprocessing and cleaning are essential steps in credit scoring projects. In Python, you can use Pandas for tasks such as handling missing values, removing duplicates, scaling features, encoding categorical variables, and more. Additionally, libraries like scikit-learn provide tools for feature selection and transformation.




.webp)
.svg.webp)









.webp)

.webp)
.webp)
.webp)



.webp)




%20(1).webp)
